Blog
Streamline and Maximize the Value of Shared Data Within an Organization
Apr 14, 2021 | Alison Marjanowski
Apr 14, 2021 | Alison Marjanowski
Imagine this scenario: An investigator sends a CV and 1572 to a CRA. The CRA records receipt of the documents on a tracker and conducts a quality check to make sure the documents meet the standard requirements. The CRA then records the QC completion on the tracker and sends the 1572 and CV into the TMF. Sometimes a second check occurs to make sure all tracked documents were subsequently filed. A submission manager then checks the tracker to see which 1572s and CVs were received. They pull the documents from the TMF and copy them into their submissions management system, where they are assembled into an Investigator Update to the IND. The submission manager then records on a tracker that the submission is complete.
At this point, the documents have moved through four different locations. Their existence and/or status was recorded in multiple different systems or trackers. The study and site number were entered in several places as well. Even with solid process control, there is always a risk of error due to the sheer number of manual interventions and the compounding effect of time across many different studies and sites.
Now, imagine if the 1572s and CVs moved automatically through all the steps in the process via workflows. Automated workflows eliminate manual intervention and automatically record the status of the file (e.g. whether it’s been received, quality checked, and submitted to FDA). The documents also carry the same shared core data through systems and steps, such as Product, Study Number, Site Number, and Investigator Name.
Understanding Why Data Governance is Essential for Shared Data
The above story highlights why sharing data and documents across functions and systems can be so valuable. But simply connecting the data and systems is not enough. In order to maximize the value from these types of connections, companies need to standardize and govern the shared core data. Data governance sets the stage for automation, increased visibility via analytics, and improved collaboration across teams.
Many large enterprise companies already have well-established and sophisticated data governance, and Master Data Management (MDM) approaches, including data warehouses. But how can small and medium-sized biopharma companies get started with data governance when they don’t have the means to implement an MDM or data warehouse?
Setting Priorities
First, consider which connections would advance your company’s priorities and goals. For example, is it your goal to accelerate the development of a platform-based pipeline with a high number of interrelated indications? Or is it your goal to harmonize change management across multiple regions and products? Starting at this high level can help you drill down into specific processes and functions that would bring the biggest impact for your immediate need.
The next step is to understand how much effort is required to design or update the processes and systems around the connection points. Effort includes things like system upgrades, configurations, integrations, and data migration, but it also includes new processes and change management. Your unique company culture can heavily influence this, so it’s not a one-size-fits-all effort.
From there, you get a clear picture of the highest impact connections with the relative effort required to implement them. You can use that to design a roadmap and/or set priorities.
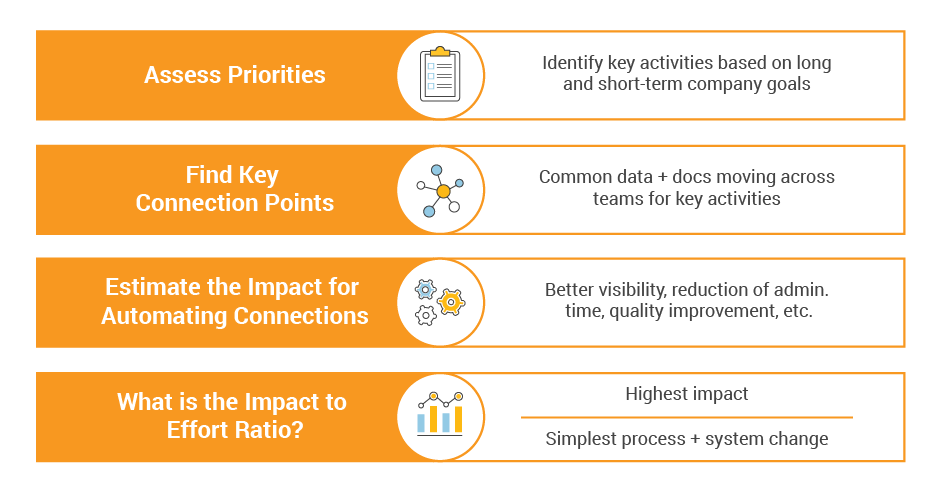
Consider the Potential Future State
Once you understand the cross-functional impact for your business and immediate connection points, consider the future state so you can keep those newly defined dependencies in mind moving forward. A great way to work backward from your future state is to look at the IDMP model. You can identify which pieces of data are relevant to your organization in its current stage and which data will be applicable as you progress through development.
In addition to IDMP, it’s a good idea to keep an eye on other structured data submissions required by global health authorities (HA) and what new initiatives are in the works, such as KASA/PQ-CMC, eLabeling, etc. You can concentrate on areas where the same data is used multiple times across your organization, even if it’s not part of a structured data requirement or HA controlled vocabulary.
Many of our customers are going through this planning and assessment right now.
Shared Data Model Design
After thinking through your future state and your immediate desired connections, it’s time to build out a shared data model to be governed. The phrase “data model” can be intimidating to people, but it’s simply a map of data and how it’s linked. You can start with the basics and make it more complex over time. It doesn’t have to be all-encompassing when you start.
Focus on that first connection point or points that you plan to streamline, clean, or automate. Identify the data elements in each system that have cross-functional and/ or cross-system impact. Examples include things like new investigator updates, protocol amendments, CMC-related change controls, and other post-approval or investigational changes to a product, which share the common data elements of product, site, study and submission. You need to standardize the common data that is part of this connection, so make sure you have a process or system that allows you to control the format and terminology. Standardization can be as simple as a picklist or controlled vocabulary.
Some types of data may need to be presented one way for business purposes but another way for HA reporting requirements. In this case, you can develop a controlled process to map them over, so you maintain that flexibility, but be sure to limit this approach to cases where there is a solid advantage for having two forms of the data.
As part of your design, you should identify the systems and organizations responsible for creating and maintaining those data elements, i.e. where the data are “mastered”. Examples include product and manufacturing site, which can be owned by your supply chain; study number, which can be owned by clinical operations; and registrations, submissions, and approvals, which can be owned by regulatory.
Use this information to develop a data map of these key data elements, their owners, their master systems, as well as the downstream consumers of master data. The below example shows an illustrative and simple data model for a clinical stage company who is evaluating sharing data across regulatory, quality and clinical. Consider migrating this to a swim lane format leveraging your specific business processes, so you can show where the data originates and where it is consumed for each function.
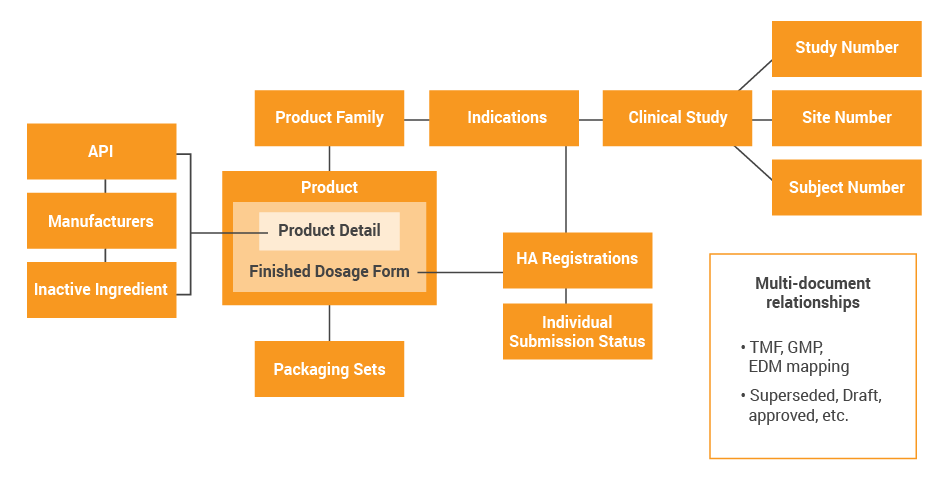
Shared Data Governance
After creating a basic data map, you can then build out a governance team and a basic charter. One of the main goals of data governance includes monitoring compliance to ensure process adherence. Assign stakeholders from IT and business for every group that owns or consults that data. And most importantly, you need a leader who can work across functions with impartiality. Usually, this is an IT-Business Liaison, but it can also be a unique role. It’s also quite helpful to get senior leadership involved as a sponsor to ensure that all parties understand the importance of alignment.
With a data governance team in place, you should then set up processes to manage changes to your master data, including a method to propose changes and assess impact to data consumers.
Data-centric Evolution
Your governance team can also branch out beyond the core shared data governance and help with change management across the organization by evaluating planned company or process changes through a data-centric lens.
For example, if your company wants to make a change to a process that involves increased data entry then your governance team can assess whether the value is worth the additional data entry effort. They can also help you understand where that data may provide a new insight or automate a manual step. This type of data-centric thinking will help companies prepare for future changes and ultimately improve their business outcomes.
Furthermore, HAs have made it clear that they are moving towards a more data-centric future. The advantages of this approach are clear: easier data consumption and more robust analysis. Moving your company towards a data-centric approach will allow you to reap the same benefits, even if you start with a simple approach.
To learn more about how biopharma companies can work more efficiently across domains, visit the Vault Connections Resource Hub.